
Machine Learning vs. Statistics: What’s the Best Approach?
Reviewed by Gerri Dunnigan, Ph.D.
The best approach between statistics vs. machine learning depends on your goals.
Request Information
Machine learning is ideal for predictive accuracy with large datasets, while statistics is better for understanding relationships and drawing clear conclusions.
When it comes to machine learning vs. statistics, opinions often fall into two camps: those who see little difference between the two and those who believe they are entirely separate fields. The truth lies somewhere in the middle.
While machine learning and statistics certainly differ in their approaches and tools, they are deeply interconnected. Understanding their similarities and differences is key to appreciating how these two disciplines complement each other in the world of data analysis.
What is Machine Learning?
Machine learning is a branch of computer science that focuses on developing algorithms and models through which computers can learn and even be used to make decisions by themselves based on data. Unlike traditional programming, where specific instructions are provided, machine learning models identify patterns and make predictions by analyzing large datasets.
There are three primary types of machine learning: supervised, unsupervised, and reinforcement learning. In supervised learning, models are trained on labeled data, meaning that each input is paired with a corresponding output. This method is commonly used for classification and regression tasks, such as predicting whether an email is spam.
Unsupervised learning, on the other hand, deals with data that has no explicit labels. The model attempts to discover hidden patterns or structures within the data. It is often used for clustering, where similar data points are grouped, and association, which identifies relationships between variables.
Lastly, reinforcement learning involves training a model through interaction with an environment, where it receives feedback in the form of rewards or penalties. The goal is for the model to learn a policy that maximizes cumulative rewards over time. This approach is most suitable for applications like robotics, game-playing, and autonomous systems.
What is Statistics?
Statistics is the branch of applied mathematics that deals with the collection, analysis, interpretation, presentation, and organization of data. It provides various tools and methods that professionals can use to make sense of data, draw conclusions, make predictions, and make informed decisions based on empirical evidence.
Descriptive statistics and inferential statistics are two fundamental sub-branches of statistics. The first involves methods for summarizing and organizing data in a way that provides a clear and understandable overview of the information. This branch is focused on describing the main features of a dataset through measures of central tendency and measures of variability.
Inferential statistics, in contrast, is concerned with making predictions or inferences about a larger population based on a sample of data. Since it is often impractical or impossible to gather data from an entire population, inferential statistics allow us to make generalizations by analyzing a representative sample.

The Difference Between Machine Learning and Statistics
Machine learning and statistics are two fields that often overlap, yet they have distinct goals, approaches, methodologies, and applications. Although both are concerned with data analysis and inference, they differ in how they approach problems and the techniques they use.
Goal
The primary goals of machine learning and statistics set the foundation for their differences. In statistics, the main objective is to understand relationships between variables, make predictions, and provide explanations based on data. Statisticians aim to model uncertainty and quantify the strength of evidence in support of hypotheses. The focus is often on understanding the underlying processes that generate the data and providing interpretable results that can inform decision-making.
In contrast, machine learning aims to develop algorithms that can learn from data and make accurate predictions or decisions without being explicitly programmed. Machine learning practitioners are more concerned with building models that perform well on unseen data, often prioritizing predictive accuracy over interpretability. The focus is on the model's performance in practical applications, such as classifying images, recognizing speech, or predicting user behavior.
Approach
The approach in statistics is traditionally hypothesis-driven. Statisticians begin with a hypothesis or a model that describes the relationship between variables and then test this model against the data. This approach often involves formulating null and alternative hypotheses and using p-values, confidence intervals, and other statistical measures to draw conclusions about the data.
On the other hand, machine learning adopts a more data-driven approach. Rather than starting with a predefined hypothesis, machine learning models are trained on large datasets to learn patterns and relationships directly from the data. This process often involves splitting the data into training and testing sets, where the model learns from the training data and evaluates its performance on the test data.
Methodology
The methodologies used in statistics and machine learning are a reflection of their different goals and approaches. In statistics, the methodology is often grounded in probability theory and involves techniques such as linear regression, logistic regression, ANOVA, and time series analysis. These methods are designed to infer relationships between variables, test hypotheses, and provide estimates with clear interpretations.
Machine learning, in contrast, employs a broader range of algorithms, many of which are non-parametric and do not rely on strict assumptions about the data distribution. Common machine learning techniques include decision trees, random forests, support vector machines, neural networks, and deep learning models. These algorithms are designed to handle large amounts of data and complex patterns, often using techniques such as cross-validation, grid search, and ensemble methods to optimize performance.
In statistics, the methodology emphasizes the importance of model assumptions and the conditions under which the results are valid. In machine learning, however, the focus is on empirical performance, and there is less concern with model assumptions.
Model Complexity
Model complexity is another area where machine learning and statistics differ. In the latter, models are typically kept relatively simple to ensure interpretability and avoid overfitting the data. For example, a linear regression model might include only a few predictor variables, with interactions and higher-order terms included sparingly.
Machine learning models, on the other hand, can be much more complex. They often involve thousands or even millions of parameters. For instance, deep learning models, particularly neural networks with multiple layers, are capable of capturing intricate patterns in data that are beyond the reach of traditional statistical models.
Interpretability
Interpretability refers to the extent to which a model's results can be understood and explained in a human-readable form. Since statistical models are simpler, they allow for a more straightforward interpretation of the results and their implications. Meanwhile, machine learning models, particularly highly complex ones, often sacrifice interpretability for predictive power.
Data Size
Traditionally, statistics has been applied to relatively small datasets, where careful consideration of sampling, data quality, and model assumptions is essential. Statistical methods are designed to work well even with limited data, often focusing on making the most of available information through efficient estimation and inference techniques.
Machine learning, however, thrives on large datasets. The availability of big data has been a major driver of advances in machine learning, particularly in areas like deep learning. Large amounts of data allow machine learning models to learn more complex patterns and better generalize new, unseen data.
Application Areas
The application areas of machine learning and statistics also differ, although there is significant overlap. Statistics has traditionally been applied in fields such as economics, medicine, social sciences, and agriculture, where the focus is on understanding relationships between variables, testing hypotheses, and making inferences about populations.
On the other hand, machine learning has found widespread application in areas requiring automated decision-making and high predictive accuracy. These include fields such as finance, transportation, security, manufacturing, and healthcare.
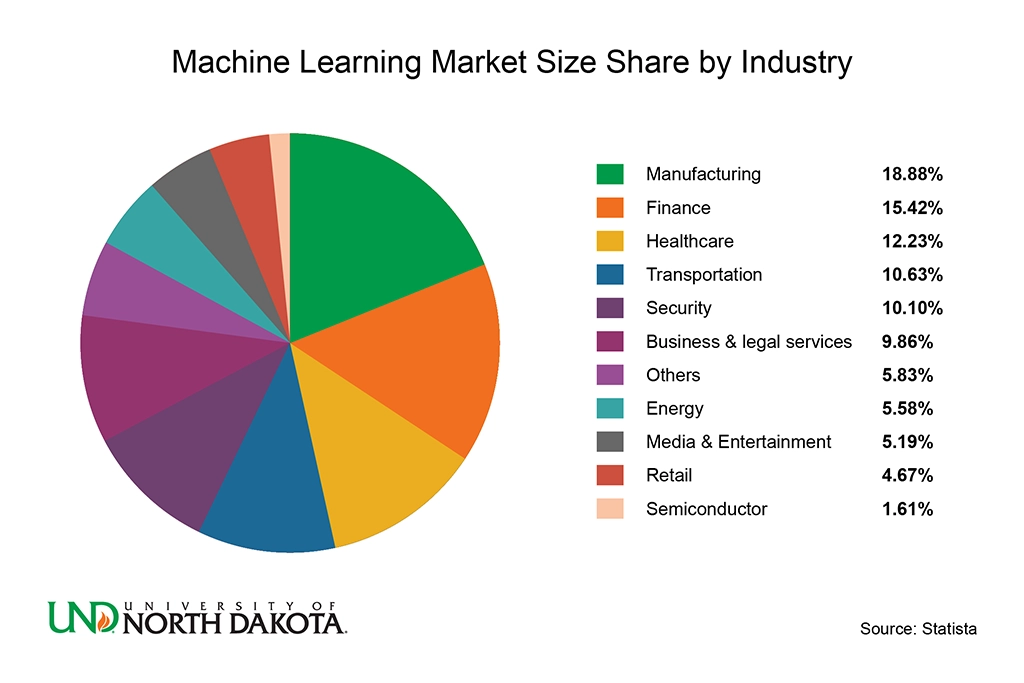
Machine Learning Market Size Share by Industry
- Manufacturing: 18.88%
- Finance: 15.42%
- Healthcare: 12.23%
- Transportation: 10.63%
- Security: 10.10%
- Business & Legal Services: 9.86%
- Others: 5.83%
- Energy: 5.58%
- Media & Engagement: 5.19%
- Retail: 4.67%
- Semiconductor: 1.61%
However, the distinction between the two fields is not absolute, and there is increasing convergence between machine learning and statistics. For example, methods from machine learning are being integrated into statistical workflows, and statistical concepts are being applied to improve the interpretability of machine learning models.
When to Use Machine Learning vs. Statistics
The choice between machine learning and statistics depends entirely on the situation and the specific goals you have in mind. In some cases, machine learning is more suitable, while in others, statistics is the better choice.
For example, if you're working with a massive dataset of customer behavior and your goal is to predict future purchases, machine learning would be the ideal tool due to its ability to handle complex patterns and large volumes of data. On the other hand, if you're conducting a medical study and need to understand the relationship between a treatment and its outcomes, statistics would be more appropriate because it provides clear, interpretable insights based on well-established methodologies.
The key is to understand what you want to learn from the data and how you intend to use it.
Skills and Tools Required
Both machine learning and statistics require a strong background in mathematics and proficiency in programming languages like Python or R. They also share some common tools like Jupyter Notebooks and RStudio, which are used in both fields for coding, experimenting with models, and visualizing data.
But, despite these similarities, machine learning and statistics diverge in their specific focuses and toolsets. Machine learning often requires deeper knowledge of advanced programming and familiarity with specialized libraries and frameworks. Additionally, because this field primarily works with large datasets, it requires tools like Apache Spark for big data processing.
In contrast, statistics is more focused on traditional statistical software. Statistical analysis often involves smaller, more structured datasets and prioritizes model interpretability, using tools like R or SAS for clear data presentation and in-depth analysis.
Conclusion
Machine learning and statistical modeling are complementary disciplines. Both are rooted in the same fundamental mathematical principles but use different tools and approaches within the broader analytics knowledge base.
At UND, you have the flexibility to pursue one, the other, or both. You can combine your degree with a Statistics Minor, or if you're focused solely on statistics, you can gain expertise with our Master's in Applied Statistics Degree Online. Additionally, our AI & Machine Learning Certificate is available for those looking to specialize in the cutting-edge field of machine learning.
In the end, whether you're crunching numbers or training models, data is the common thread that ties these fields together.
FAQs
Machine learning and statistics are closely related fields since they both focus on analyzing data to make predictions and inform decisions. They complement each other, with statistics offering the theoretical basis and machine learning applying that theory to solve complex, real-world problems.
Statistics is often better suited for understanding relationships within data, testing hypotheses, and making inferences about a population, especially when interpretability and transparency are important. However, machine learning may be better suited in situations where the primary goal is to make accurate predictions from large and complex datasets, even if the model's inner workings are less interpretable.